
AI review tools are emerging as a potential solution to our increasingly strained peer review system, but to date, there's no standardized way to evaluate them.
We built ReviewBench, a venue-agnostic, extensible benchmark framework to evaluate human and AI peer reviews. We use it to compare human reviews with Reviewer3 (R3), a multi-agent system, and two leading frontier reasoning models, GPT-5.2 and Gemini 3 Pro, across three disciplines: computer science (ICLR 2025, n = 1,000), social science (Nature Human Behaviour, n = 142), and life science (eLife, n = 1,000). The dataset consists of 145,021 review comments.
AI Reviews Are More Structured
A peer review comment can include a specification of the issue, a justification for why it matters, a remedy for how to address it, and an anchor to a location in the paper. Across all three disciplines, AI reviews are more structured than human reviews, with R3 leading on justification (96.4–97.3%) and actionability (99.2–99.9%) in every venue.
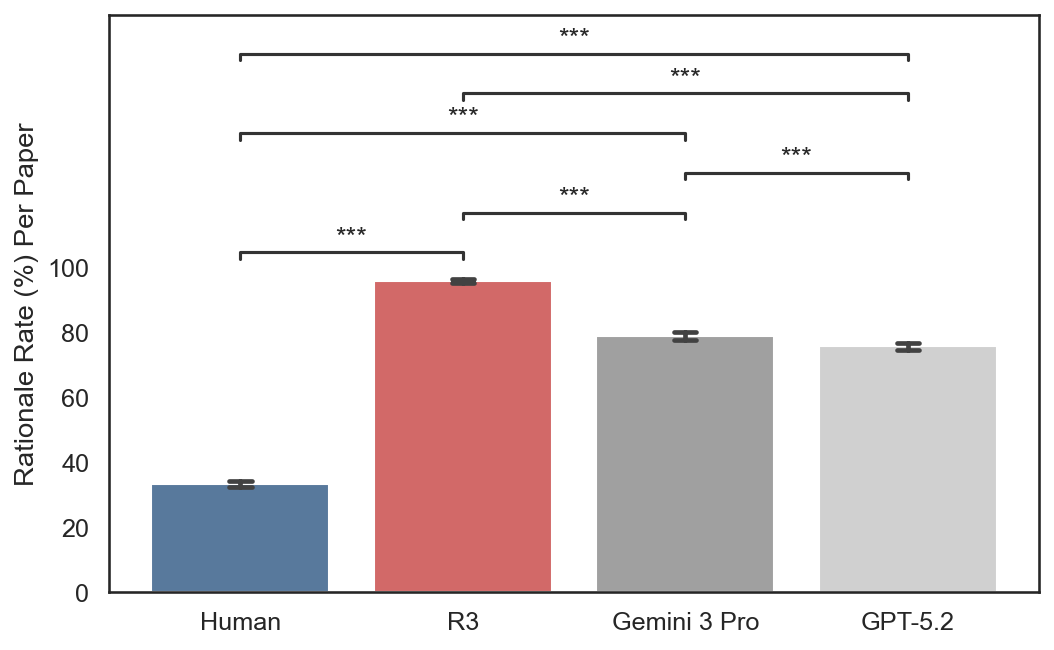
Justification rate per paper, by source across three venues.
R3 Comments Are More Frequently Consequential
For each paper, we extract 3–7 major claims and map each comment to this set. Comments can map to the same claim and stance but vary in impact. We define a consequential label for comments that, if correct, could undermine the mapped claim. R3 achieves the highest consequential rate across all three venues (87.9–93.2%), compared to 73.7–81.4% for GPT-5.2, 65.5–77.5% for Gemini 3 Pro, and 60.0–67.7% for humans.
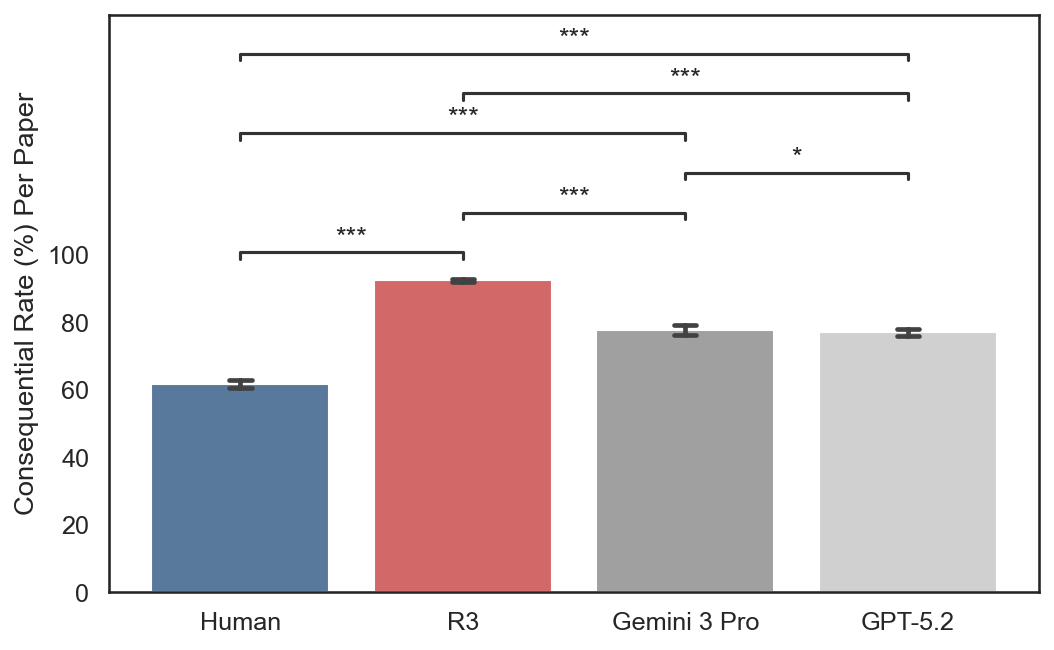
Consequential rate by source across three venues.
Agreement with Human Reviewers
We compute stance-matched overlap: the percentage of human-addressed claims that the AI source also addresses with the same dominant stance. R3 and GPT-5.2 achieve similar overlap (64.8–76.3% and 67.1–80.7%, respectively), with the highest agreement in Nature Human Behaviour. Per-paper rankings show R3 ranks first most frequently across all three venues.
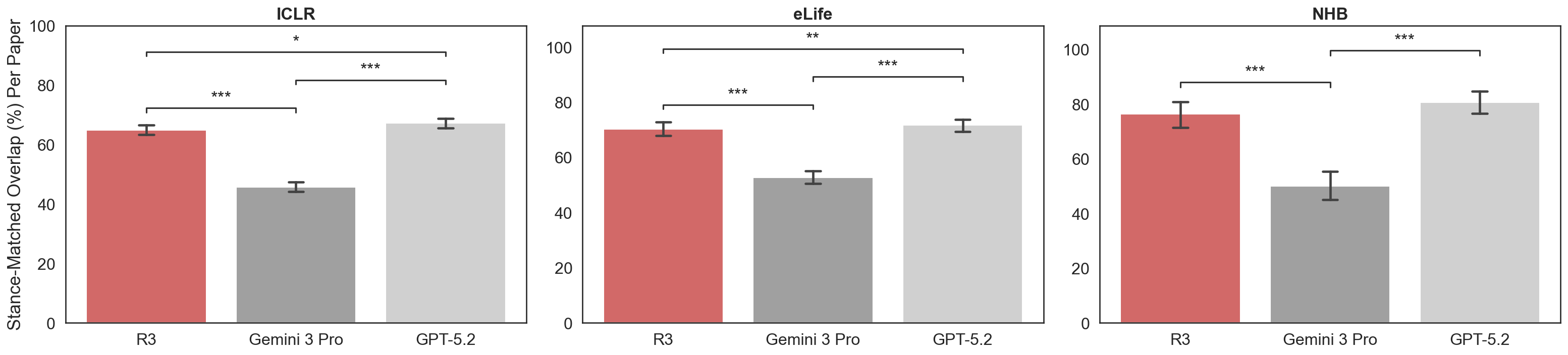
Stance-matched overlap fraction by source across three venues.

Per-paper ranking by stance-matched overlap fraction across three venues.
Humans Critique Contribution, AI Verifies
Human and AI sources provide different types of critiques. Humans focus on contribution (17.5–25.2%) and clarity, while AI sources devote more than half of their attention to validity and sufficiency, with R3 leading in validity across all three venues (34.8–46.9%).
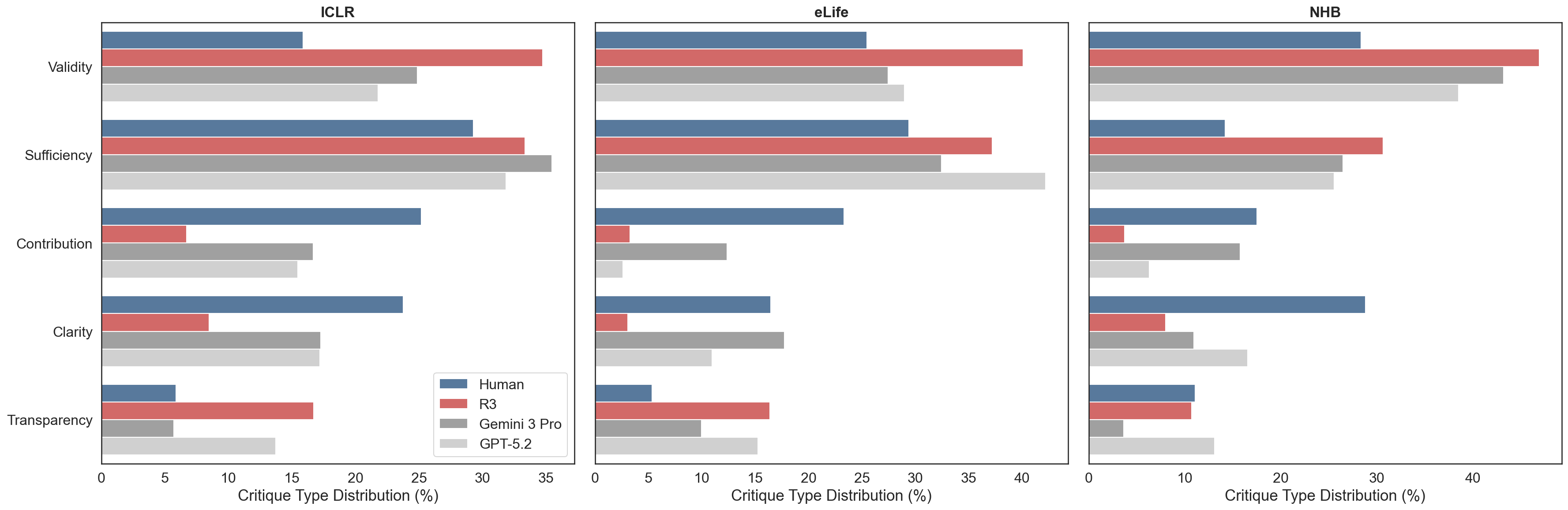
Critique type distribution by source across three venues.
What This Means
These results point to a complementary model for peer review. AI systems can audit the technical validity of major claims at scale — R3 surfaces consequential issues at rates of 87.9–93.2% across disciplines — while human judgment remains essential for evaluating a work's contribution and broader value. The framework is venue-agnostic and extensible to any AI review system, and the full dataset and code are publicly available.
Ready to see what AI peer review looks like? Try R3 on your own paper.